Alto
Date: 2020 — present
Status: Rockin'
The year was 2020. The pandemic was just beginning and I was stuck at home, not being able to do much of anything. Worse, rumours came around that Google was shutting down Google Play Music, my music player of choice. They were going to force everyone onto their streaming service instead. Oh, they may have a place for all the music you've downloaded (or written) yourself, but not in the first version. Maybe they'll get to it later.
"Well, fuck that", I said to myself. "I've been battered around by Google shutting down things and forcing migrations onto other things one to many times. I'm going build my own music app."
And so I built my own music app: Alto.
Why "Alto"? Well, the name goes back to when I was in secondary school,
when I was learning the viola, which uses the alto clef for it's written
music. I said to myself at the time that if I were ever to build a music
player, it'll have something referencing the viola. The alto clef seemed
like the best thing to use. Plus, it stands out amongst the other music
apps that tend to use other notation symbols like notes or the treble
clef.
The idea for Alto was pretty straight forward: a music player and catalogue that'll manage and stream music from an S3 bucket. No tracking, no "promotions" or "recommendations", no bullshit UI that's impossible to navigate. Only the music I'm interested in, played the way I want, and a dead simple UI that puts the album front and centre. The music player that was meant for me.
The Web Catalogue
The ultimate version that would come to be would consist of two parts: an Android mobile app, and a web-app. I'll talk about the mobile app in the next post.
The web-app can be used as a player, but is ultimately be responsible for managing the collection.
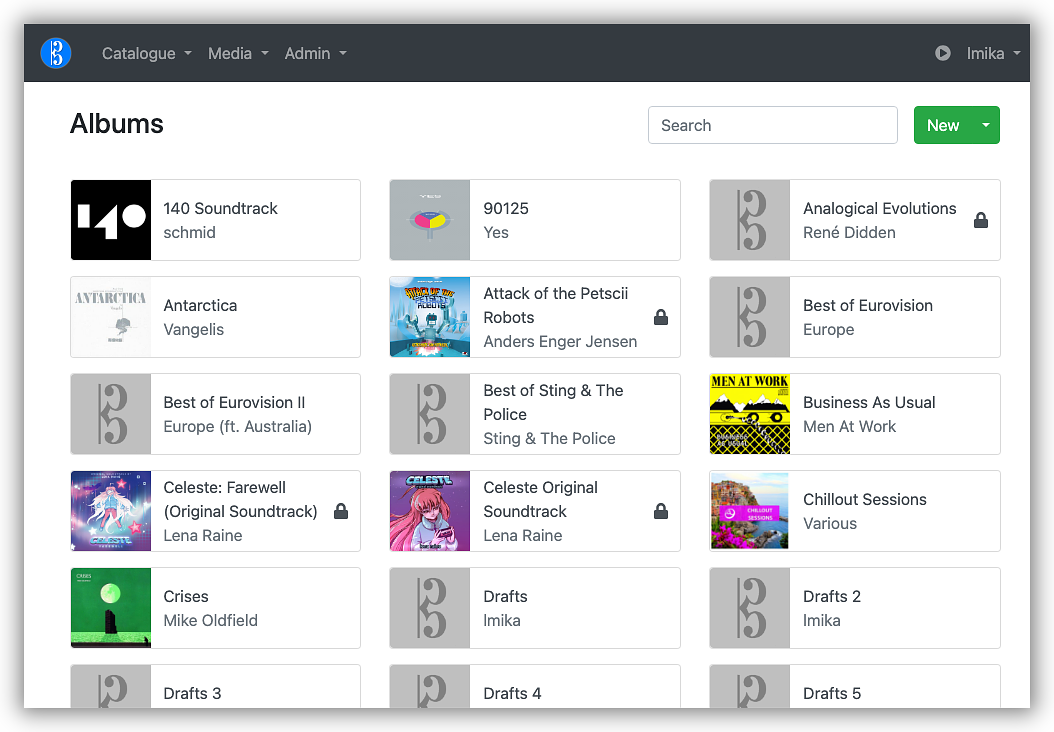
The web-app was built using Buffalo, a rapid web development much like
Rails for Go. It's basically a simple server-side rendered web-app. The
frontend consists mainly of Bootstrap plus some Stimulus and vanilla
JavaScript to handle the interactive elements.
It's also using
Turbo to prevent unloading the current page when moving to a new one.
This means clicking around the site will not stop playback of the
current track, a very nice feature (and doubly so when you consider that
this isn't a single-page app).
Much of the UI is dedicated to managing the catalogue but there is also an integrated player, which can be invoked by clicking the play button. The player itself can be bought up at any time by pressing "P". There's no scrubber but there are seek by 30 second buttons which do the job. Each of the controls in this player have associated shortcut keys that are always available, even with the player hidden.
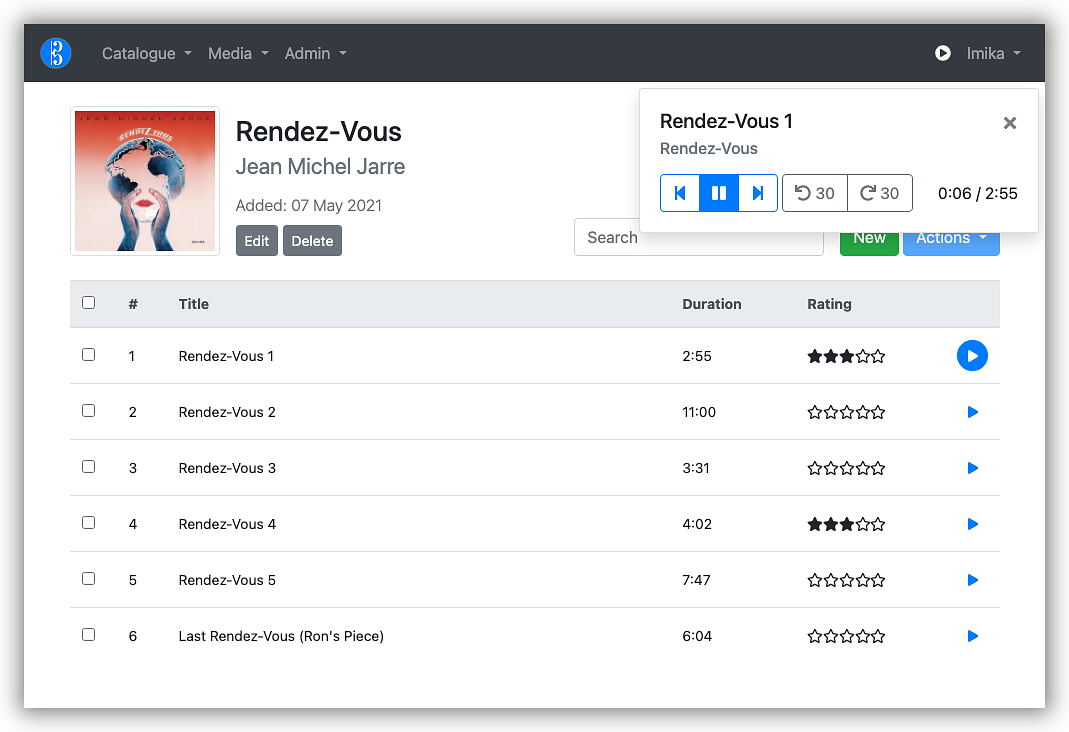
The collection is managed within a PostgreSQL database and referenced files stored on an S3 bucket. S3 was chosen to ensure that if I were ever to stop work on this project, or the database were to be corrupted, I wouldn't loose my music. It does mean that I've got an ongoing cost for running this service, but based on the amount of music I'm keeping and my music listening patterns, the monthly bill for S3 is around 50¢-60¢ AUD, plus $12.00 US for the web-app server.
The catalogue model was made as simple as possible. The main
construct is the Album, which would consist of zero or more Tracks.
Albums had things like title, artist, cover images, etc. but these are
nothing more than just properties of an album.
Tracks could be added one at a time via the frontend, or uploaded from a Zip file pulled from a URL (useful for songs bought on Bandcamp). The catalogue tries it's best to avoid uploading media via the web-server, either opting to pull it in from the backend or upload it to S3 directly. This was a deliberate choice to reduce the amount of network it uses, but it does mean going through some strange loops. For example, when uploading a single track via the frontend, it would upload it directly to S3, then download it from S3 on the backend so that it can set catalogue metadata from the file itself (ID3 tags, MP3 length, etc). This is pretty convoluted and doesn't even work half the time, and if I were making this again, I'd probably just bite the bullet and allow large uploads via the frontend.
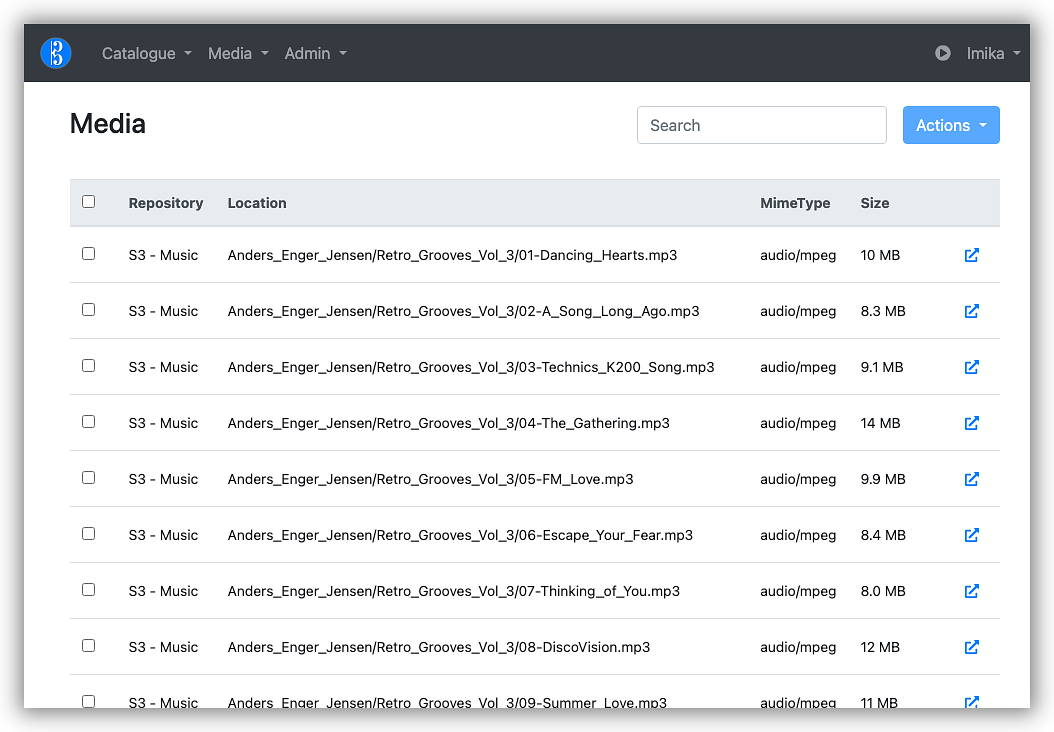
Media
The media model is a little more complicated. Media — audio files,
cover images, etc — all belonged to a Repository, which is essentially a
reference to an S3 bucket, although it could also reference things like
a HTTP domain. A repository does have some other configuration such as
how to name the uploaded media files. I could've used something like a
UUID, but I wanted to keep the names human readable as much as I could,
so that if this project were to shutdown, I would still be able to
access the files from S3 myself.
An Album or Track is linked to a Media record through what's called a Media Reference. Each of these references has a "rel" property (short for "relevance") which describes what the media is for: an audio file for a track, a cover image for an album, etc. There also exists a classifier which was to allow an Album of Track to use multiple Media records of a particular relevance. For example, some albums, released in different regions, had different album covers, with one being slightly darker than the other. The classifier could be use to switch between the two, based on whether Dark Mode was enabled. At least that was the theory: it never really got used for that.
Governing the link between albums, tracks and media was a simple resolution algorithm that supported things like inheritance. For example, tracks could have their own album cover, but if one didn't exist, they would inherit it from the album. This went beyond just album covers: it would be possible, theoretically at least, to have the audio associated with the album and have the tracks reference a different cover image (I never tried this).
Finally, there are Playlists. These are pretty standard: just a collection of references to other tracks, plus some ordering information. Playlists and playlist items are essentially links and cannot have Media References themselves. There are some downsides to this: the biggest one being that Playlists do not have album cover art, which is something I'll need to fix. Playlists can also have metadata items.
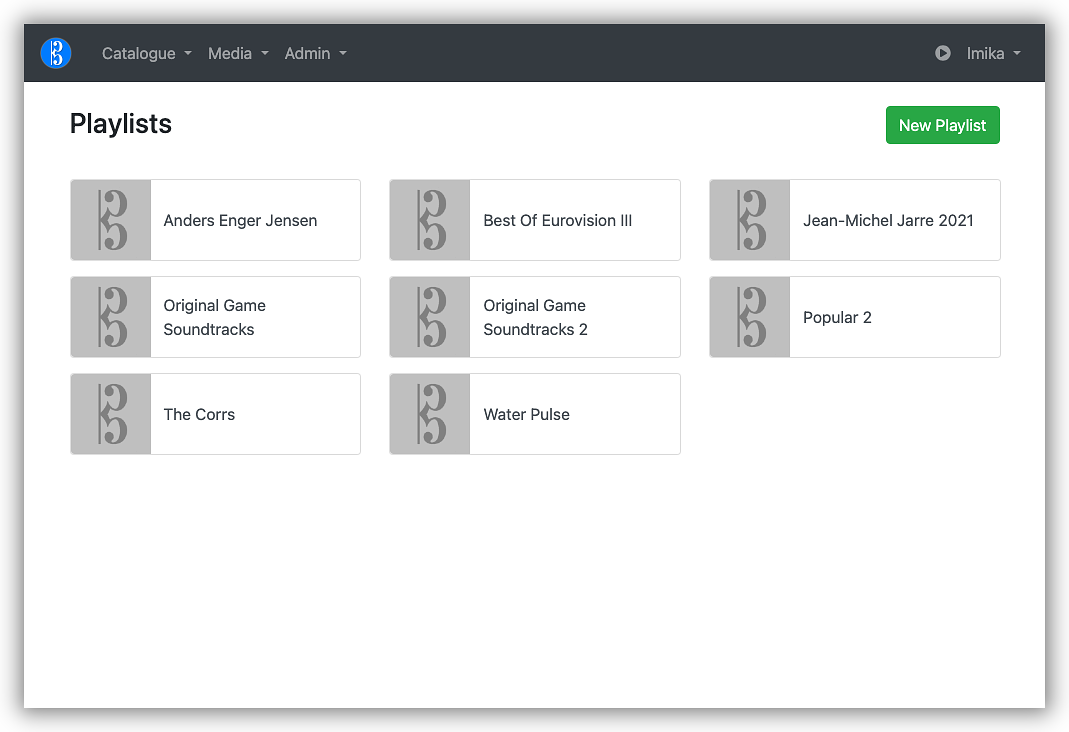
Speaking of metadata items.
Metadata Items
A number of objects can also have metadata, which could be use to
attach extra attributes. The goal was to make this generic enough for
end users to use it for whatever, with Alto having a few predefined
names it uses for it's own purpose.
There were actually two kinds of metadata record. The first was an
arbitrary JSON structure that can be set for each Track. Only one such
name was reserved, called heading, which was used to define track
groups within albums. I do have plans for adding more attributes, such
as things dedicated to Eurovision tracks (year and country for example).
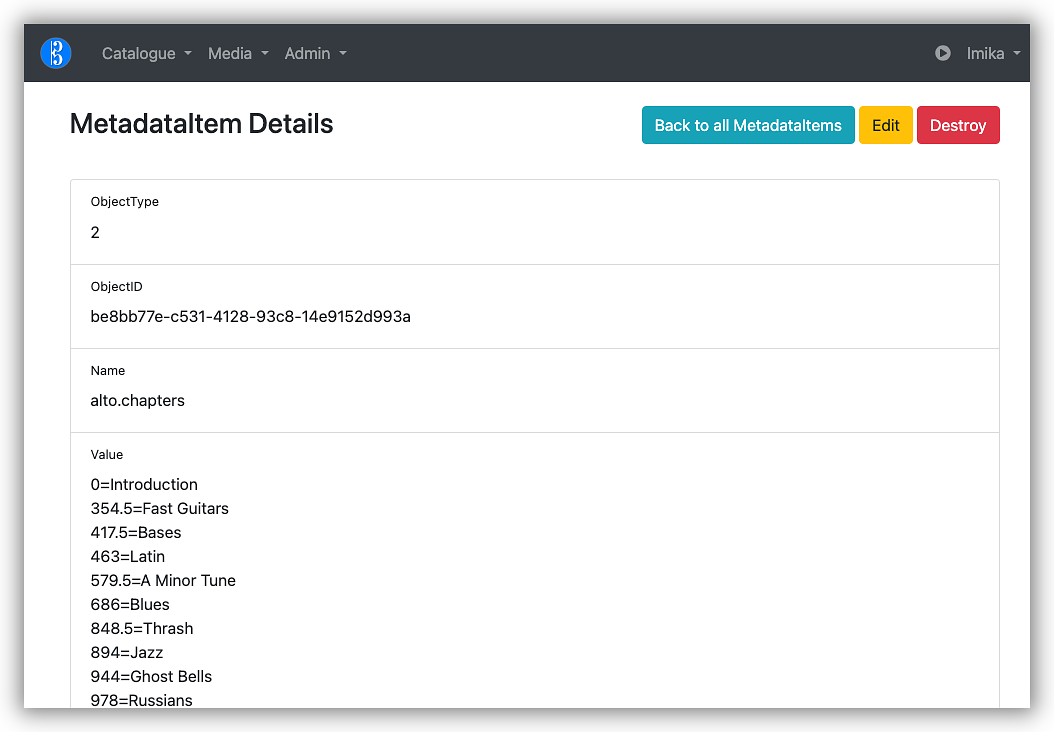
0=Intro 139.5=Outlaw 229=Crises 467.5=The Watcher and the Tower 599=Interlude 774.5=Sequencer 1111=Coda
I suppose I should find a way to extract chapters from the MP3 file itself but for the moment I'm just setting them manually. I am also using it to store things like lyrics. I should say a few words as to how Media Refs and Metadata Items actually reference other things in the model. They use a notion of "object_type" and "object_id" which describes what the object is (album, track, playlist item, etc.) and object ID referencing the actual object itself. Because this is quite generic, I can't rely on ON DELETE CASCADE to clean these up, so I opted for database triggers to remove media refs and metadata items when the base object type is removed.
CREATE FUNCTION delete_dependencies_of_object() RETURNS trigger AS $$ BEGIN DELETE FROM media_references WHERE object_id = OLD.id; DELETE FROM metadata_items WHERE object_id = OLD.id; RETURN NULL; END; $$ LANGUAGE plpgsql; CREATE TRIGGER delete_dependencies_of_tracks AFTER DELETE ON tracks FOR EACH ROW EXECUTE PROCEDURE delete_dependencies_of_object(); CREATE TRIGGER delete_dependencies_of_albums AFTER DELETE ON albums FOR EACH ROW EXECUTE PROCEDURE delete_dependencies_of_object();
So far I haven't had any issues with this, although I haven't done a lot of snooping around the database to confirm these records are properly being cleaned up.
Grand Plans
I did have grand plans for this catalogue at one point: releasing it as open source, maybe making this a service that others could use. So there were a few things added which are unfinished and half baked. Some examples:
- Having multiple catalogues with different access roles.
- Feature flags, which disabled certain features for users.
- Generating a QR code for an API token for easy sign in on the mobile app.
None of these really went anywhere, and if I were to rebuild this, I'd probably pull them out. As things stand now, it does need a bit of a refresh: upgrading Go packages, dealing with Node packages (ugh, it's always a pain trying to update JS packages and Webpack). But since around late 2020, it's been serving quite well as my primary music player.